Zwei Personen stellen derselben KI dieselbe Frage – und kommen zu völlig unterschiedlichen Urteilen. Die eine spricht von einer erstaunlich präzisen und hilfreichen Antwort. Die andere hält sie für oberflächlich oder unzuverlässig.
Solche Situationen sind nicht ungewöhnlich. Sie verweisen auf eine grundlegende Frage: Wovon hängt es eigentlich ab, ob ein KI-Ergebnis als gut oder schlecht bewertet wird?
Naheliegende Antworten liegen schnell bereit. Die Qualität des Modells spielt eine Rolle: Leistungsfähigere Systeme liefern in der Regel bessere Ergebnisse. Ebenso relevant ist die Kompetenz der Nutzenden: Wer klar formuliert, gezielt nachfragt und Ergebnisse einordnen kann, erhält oft bessere Resultate.
Ein einfaches Beispiel:
Eine Person bittet die KI um eine „kurze Zusammenfassung“ und erhält einen allgemeinen Überblick. Eine andere formuliert präziser, grenzt das Thema ein und fordert eine strukturierte Darstellung mit Beispielen – und bekommt eine deutlich differenziertere Antwort. Unterschiedliche Nutzung führt zu unterschiedlichen Ergebnissen.
Auch bei identischem Output zeigt sich ein ähnlicher Effekt:
Eine Person nutzt die Antwort als erste Orientierung und bewertet sie als hilfreich. Eine andere erwartet eine belastbare Grundlage für eine Entscheidung – und ist enttäuscht.
Technik und Kompetenz erklären also einen Teil der Unterschiede. Sie erklären jedoch nicht vollständig, warum identische Ergebnisse unterschiedlich bewertet werden.
Erwartungen als Maßstab der Bewertung
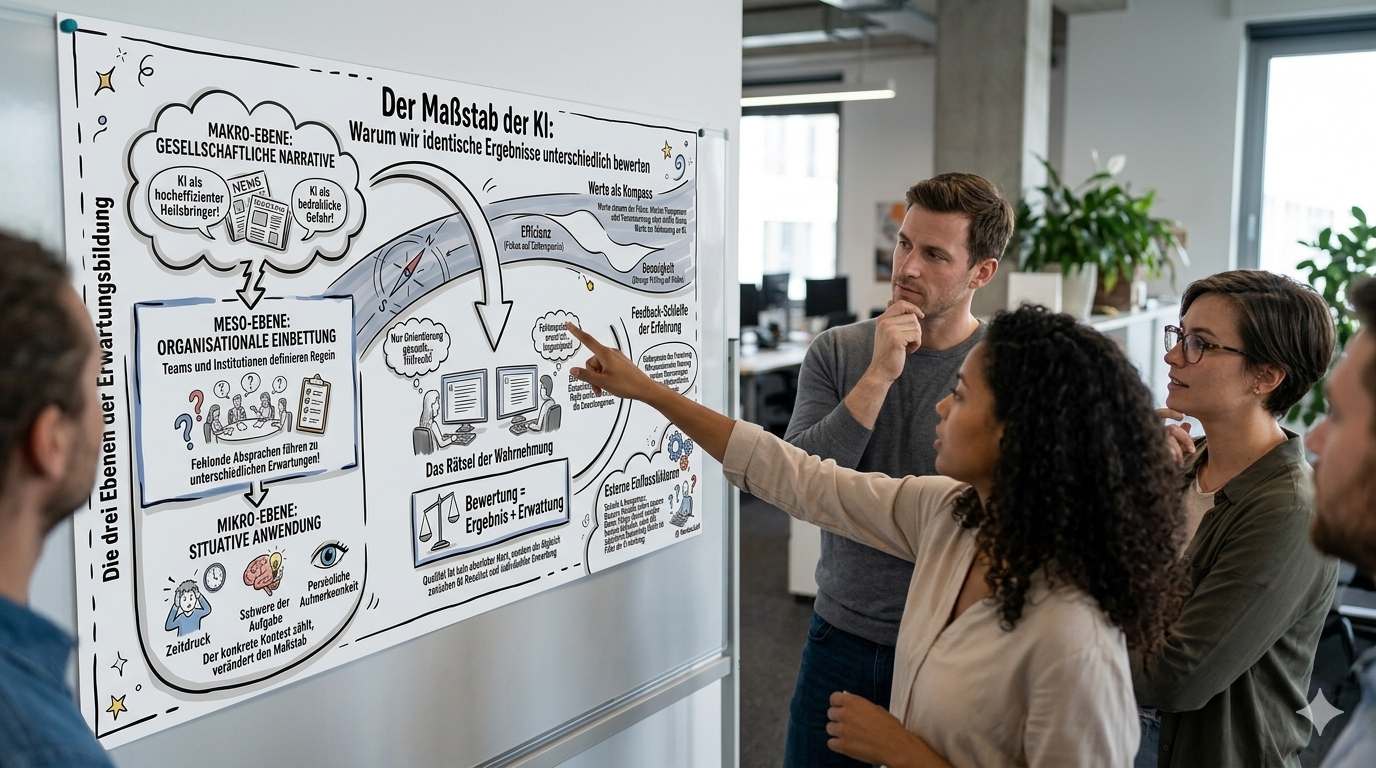
Was in diesen Situationen sichtbar wird: Bewertungen entstehen nicht allein aus dem Ergebnis selbst, sondern aus dem Verhältnis zwischen Ergebnis und Erwartung.
Wer eine erste Orientierung sucht, bewertet eine allgemeine Antwort anders als jemand, der auf Präzision angewiesen ist. Was als „gut“ gilt, ist nicht absolut, sondern hängt davon ab, was zuvor erwartet wurde.
Die Bewertung eines Ergebnisses ist daher keine unmittelbare Messung seiner Qualität. Sie ist eine Einordnung – und damit eine Interpretation.
Diese Perspektive verschiebt den Fokus. Nicht nur die Frage, was KI leisten kann, ist entscheidend, sondern auch, mit welchen Erwartungen wir ihre Ergebnisse betrachten.
Woher kommen diese Erwartungen?
Erwartungen entstehen nicht erst in der konkreten Nutzung. Sie sind bereits vorher geprägt.
Wer sich mit KI beschäftigt, begegnet ihr zunächst in Berichten, Diskussionen und öffentlichen Debatten. Dort wird sie als effizient beschrieben, als objektiv, als Werkzeug zur Entlastung – aber auch als Bedrohung: als Technologie, die Abhängigkeiten verstärkt, Fähigkeiten verkümmern lässt oder zunehmend autonom Entscheidungen trifft. Solche Zuschreibungen bleiben nicht folgenlos. Sie strukturieren, oft unbemerkt, was wir für realistisch halten
Wenn KI als zeitsparend gilt, wird Zeitersparnis zum Maßstab. Wenn sie als objektiv erscheint, wird ihren Ergebnissen eher vertraut. Wenn sie als entlastend beschrieben wird, entsteht die Erwartung, dass Arbeit reduziert wird.
Diese Erwartungen wirken weiter, auch wenn sie nicht ausdrücklich reflektiert werden, und beeinflussen zugleich, ob und mit welcher Haltung wir KI überhaupt einsetzen.
Erwartungen entstehen nicht nur im Diskurs
Gleichzeitig bleiben Erwartungen nicht auf der Ebene öffentlicher Debatten stehen. Sie werden in konkreten Kontexten weiter geformt.
Organisationen, Institutionen oder Arbeitskontexte übersetzen allgemeine Vorstellungen in konkrete Anforderungen. In einem Team kann etwa gelten, dass KI vor allem zur Beschleunigung von Prozessen eingesetzt werden soll. In einem anderen Kontext fehlt eine solche gemeinsame Orientierung: In einem Team gibt es keine klare Absprache darüber, wie KI eingesetzt werden soll. Einige nutzen sie intensiv zur Beschleunigung ihrer Arbeit, andere vermeiden sie weitgehend oder prüfen Ergebnisse sehr kritisch. Dadurch entstehen unterschiedliche Erwartungen an Qualität und Verlässlichkeit – und dieselben Ergebnisse werden unterschiedlich bewertet. Solche Rahmenbedingungen beeinflussen, was von KI erwartet wird – und wie ihre Ergebnisse bewertet werden.
Erst in der konkreten Situation werden diese Erwartungen praktisch wirksam. Eine Antwort kann für einen ersten Entwurf ausreichen, aber für eine Entscheidung ungenügend sein. Die gleiche Person kann identische Ergebnisse unterschiedlich bewerten, je nachdem, wofür sie sie benötigt – aber auch, in welchem Zustand sie sich befindet: ob sie unter Zeitdruck steht, wenig oder viel Stress hat oder die Aufgabe mit hoher Aufmerksamkeit bearbeitet.
Erwartungen als Verbindung zwischen Kontext und Bewertung
Betrachtet man diese Ebenen zusammen, wird ein Muster sichtbar.
Erwartungen werden gesellschaftlich vorgeprägt, in konkreten Kontexten weiter geformt und in der Nutzungssituation aktiviert. Sie verbinden damit unterschiedliche Ebenen – von allgemeinen Vorstellungen bis zur konkreten Bewertung eines Ergebnisses.
Die Bewertung selbst entsteht genau an diesem Punkt: dort, wo eine situativ aktivierte Erwartung auf ein konkretes Ergebnis trifft.
Was als angemessen gilt, ist somit kein fester Maßstab, sondern das Ergebnis eines Abgleichs.
Werte als stiller Hintergrund
Erwartungen entstehen jedoch nicht im luftleeren Raum. Sie sind eng mit Wertvorstellungen verbunden.
Wer Effizienz priorisiert, wird Zeitersparnis stärker gewichten. Wer großen Wert auf Genauigkeit legt, wird strenger prüfen. Wer Transparenz fordert, wird Ergebnisse hinterfragen, die nicht nachvollziehbar erscheinen.
Werte wirken dabei oft im Hintergrund. Sie bestimmen, was als wünschenswert gilt, ohne dass sie immer ausdrücklich benannt werden. Gleichzeitig können sie dazu führen, dass KI bewusst nicht eingesetzt wird – etwa dann, wenn Anforderungen an Verlässlichkeit, Verantwortung oder Nachvollziehbarkeit nicht erfüllt erscheinen.
Die Bewertung von KI-Ergebnissen ist daher nicht nur eine technische oder kognitive, sondern auch eine normative Angelegenheit.
Erwartungen verändern sich
Erwartungen sind nicht stabil. Sie verändern sich im Verlauf der Nutzung.
Wer wiederholt mit KI arbeitet, sammelt Erfahrungen: mit überzeugenden Ergebnissen, aber auch mit Fehlern oder Grenzen. Diese Erfahrungen wirken zurück auf die eigenen Erwartungen. Sie werden angepasst, differenzierter, manchmal auch kritischer.
Eine anfängliche Annahme – etwa, dass KI zuverlässig Zeit spart – kann sich im Alltag relativieren, wenn zusätzlicher Prüfaufwand entsteht oder Anforderungen steigen. Umgekehrt kann sich Skepsis verringern, wenn sich bestimmte Anwendungen als zuverlässig erweisen.
Bewertung ist daher kein einmaliger Akt, sondern Teil eines fortlaufenden Prozesses, in dem Erwartungen immer wieder überprüft und verändert werden.
Eine verschobene Perspektive
Wenn man diese Zusammenhänge ernst nimmt, verändert sich der Blick auf generative KI.
Die Frage ist dann nicht mehr allein, wie leistungsfähig ein System ist. Entscheidend wird vielmehr, unter welchen Erwartungen sie genutzt wird und wie ihre Ergebnisse eingeordnet werden – und wie diese Erwartungen zustande kommen.
Bewertungen erscheinen weniger als unmittelbare Reaktion auf Qualität, sondern als Ergebnis eines Zusammenspiels: von gesellschaftlichen Vorstellungen, konkreten Einsatzkontexten, individuellen Wertmaßstäben und situativen Anforderungen.
Eine Einladung zur Reflexion
Diese Perspektive führt nicht zu einer einfachen Handlungsanweisung. Sie verschiebt jedoch den Ausgangspunkt.
Ein reflektierter Umgang mit KI beginnt nicht erst bei der Bewertung eines Ergebnisses, sondern bei der Frage, welche Erwartungen man an dieses Ergebnis richtet. Welche Vorstellungen habe ich übernommen? Welche Maßstäbe lege ich an? Und in welcher Situation nutze ich das Ergebnis?
Solche Fragen machen sichtbar, dass der Umgang mit KI nicht nur eine Frage der Technik ist. Er ist auch eine Frage der eigenen Maßstäbe – und der Bereitschaft, diese zu überprüfen.