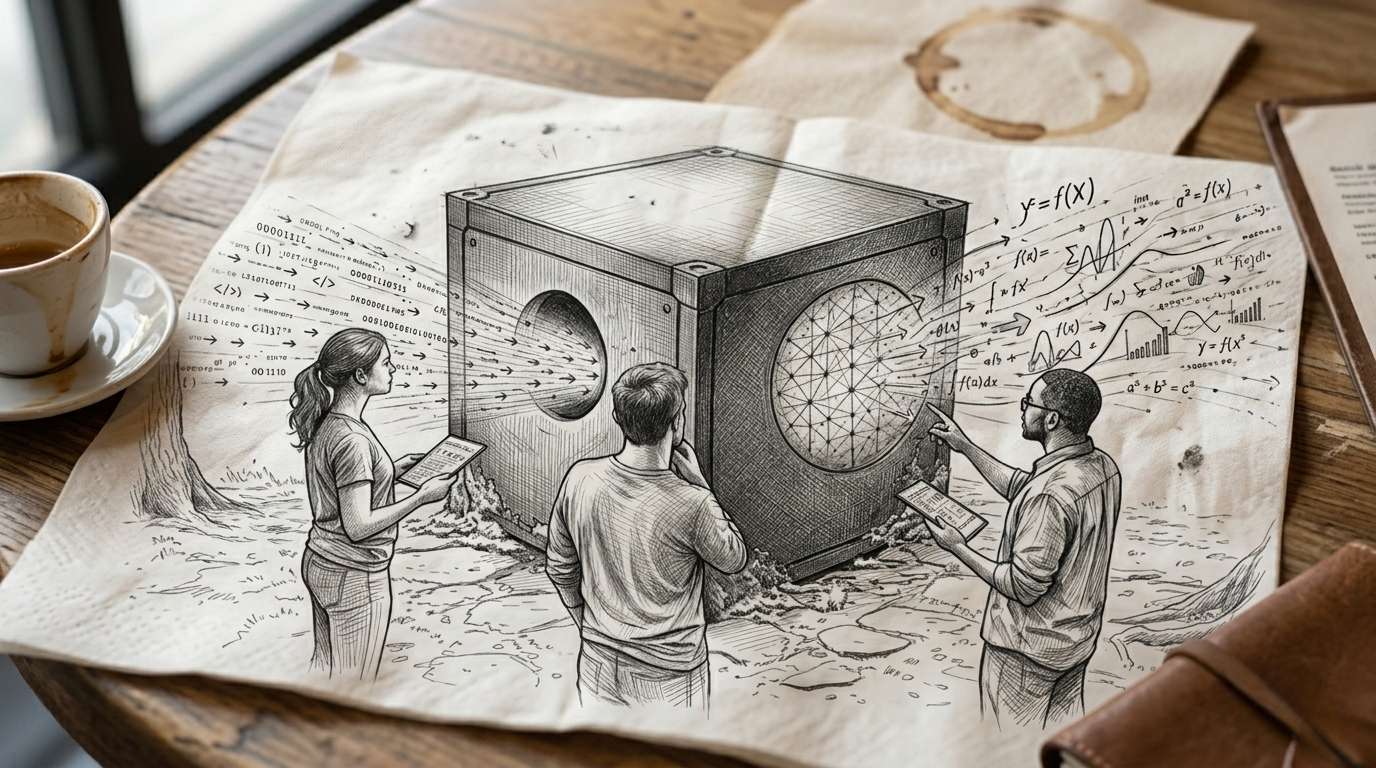
Künstliche Intelligenz wird häufig als „Black Box“ beschrieben. Gemeint ist ein System, dessen innere Funktionsweise weitgehend verborgen bleibt und das vor allem über seine Ergebnisse beurteilt wird. Gerade bei Sprachmodellen wirkt dieses Bild zunächst plausibel: Eine Eingabe wird formuliert, eine Antwort erscheint – der Weg dazwischen bleibt unsichtbar.
Lange Zeit war diese Beschreibung auch aus wissenschaftlicher Perspektive nachvollziehbar. Die Funktionsweise großer Sprachmodelle galt als schwer verständlich, da sie auf komplexen statistischen Verfahren basiert. In der öffentlichen Wahrnehmung verstärkte sich daraus die Vorstellung eines Systems, das zwar häufig brauchbare Ergebnisse liefert, dessen Funktionsweise jedoch schwer einschätzbar bleibt und dessen konkrete Ausgaben teilweise überraschend wirken.
Fortschritte in der Forschung: Ein Blick in die Architektur
In den vergangenen Jahren hat sich dieses Verständnis jedoch deutlich differenziert. Die Forschung zu großen Sprachmodellen ermöglicht zunehmend Einblicke in deren innere Struktur. Auch wenn viele Prozesse weiterhin schwer überschaubar sind, lässt sich heute genauer beschreiben, wie diese Systeme arbeiten.
Im Kern basieren große Sprachmodelle auf Deep-Learning-Verfahren, insbesondere auf neuronalen Netzwerken mit einer spezifischen Architektur (z. B. Transformer-Modelle). Diese bestehen aus vielen Schichten miteinander verbundener Recheneinheiten, in denen Eingaben schrittweise verarbeitet und gewichtet werden.
Sprachmodelle umfassen eine sehr große Anzahl an Parametern, die zunächst durch Training auf umfangreichen Textdaten und anschließend häufig durch menschliches Feedback weiter angepasst werden. Auf diese Weise lernen sie, sprachliche Muster zu erkennen und fortzuführen.
Wissen wird dabei nicht als Sammlung einzelner Fakten gespeichert, sondern in Form statistischer Beziehungen zwischen Begriffen und Konzepten. Daraus entstehen übergreifende Muster („Features“), die etwa Regeln, Stile oder thematische Zusammenhänge repräsentieren. Häufig wird dies als mehrdimensionaler Raum beschrieben – vereinfacht gesagt eine Art Landkarte, auf der inhaltlich verwandte Begriffe näher beieinanderliegen als unverbundene.
Diese Struktur entsteht nicht willkürlich, sondern bildet statistische Zusammenhänge aus den Trainingsdaten ab. Begriffe wie „Gesetz“ und „Gerechtigkeit“ treten häufig gemeinsam auf und werden im Modell entsprechend eng verknüpft. Die Architektur sorgt dafür, dass solche Beziehungen bei der Generierung von Text berücksichtigt werden.
Gewichtung statt Überzeugung: Wie Modelle „entscheiden“
Ein zentraler Mechanismus moderner Sprachmodelle ist die fortlaufende Gewichtung von Informationen. Bei jeder Ausgabe wird neu berechnet, welche Aspekte im jeweiligen Kontext relevant sind. In einem Kochrezept werden andere Zusammenhänge aktiviert als in einem politischen Kommentar oder einem Alltagsgespräch.
Diese kontextabhängige Auswahl bildet die Grundlage für alle weiteren Verarbeitungsschritte.
Diese Prozesse folgen keiner Intuition oder Überzeugung im menschlichen Sinne, sondern statistischen Wahrscheinlichkeiten. Das Modell berechnet, welche Wortfolgen unter den gegebenen Bedingungen am plausibelsten sind.
Man kann sich die Verbindungen zwischen einzelnen Konzepten, Begriffen oder Regeln so vorstellen, dass das KI-Modell im Zuge des Trainings sie in einem dreidimensionaler Raum komprimiert ablegt. In den zugrunde liegenden Repräsentationsräumen zeigt sich dies unter anderem daran, dass die Nähe oder Distanz von Datenpunkten (sogenannten Einbettungen) etwas über den Grad ihrer inhaltlichen Verknüpfung aussagt. Gleichzeitig gibt die Stärke aktivierter Muster („Features“) Hinweise darauf, welche Aspekte im jeweiligen Kontext besonders gewichtet werden.
In der Forschung wird zunehmend versucht, solche Aktivierungen sichtbar zu machen und bestimmten Funktionen zuzuordnen. In einzelnen Fällen lässt sich experimentell nachvollziehen, wann etwa Ironie, Höflichkeit oder ein Themenfeld besonders stark berücksichtigt wird.
Maschinelle Interpretierbarkeit: Ein Blick in die Black Box
Ein zentraler Forschungsansatz ist die sogenannte maschinelle Interpretierbarkeit. Ziel ist es, interne Prozesse so zu analysieren, dass nachvollziehbar wird, wie bestimmte Ergebnisse zustande kommen. Das Modell wird dabei nicht mehr nur als Black Box betrachtet, sondern als System, dessen Abläufe zumindest teilweise rekonstruiert werden können.
Diese Perspektive macht deutlich: Sprachmodelle folgen keiner mysteriösen Logik, sondern mathematisch strukturierten Prozessen. Die Herausforderung liegt in ihrer enormen Komplexität. Millionen bis Milliarden von Parametern wirken gleichzeitig zusammen und erzeugen ein Geflecht von Abhängigkeiten, das sich nur in Ausschnitten analysieren lässt.
Ein häufig verwendetes Erklärungsmodell ist dabei die Idee der Kompression: Während des Trainings werden große Mengen an Daten so verarbeitet, dass wiederkehrende Muster in kompakter Form im Modell abgebildet werden. Wie genau diese komprimierten Strukturen organisiert sind und nach welchen Prinzipien sich einzelne Features zueinander verhalten, ist jedoch weiterhin Gegenstand aktueller Forschung.
Neuere Ansätze zeigen zudem, dass sich einzelne dieser Muster in experimentellen Kontexten teilweise gezielt beeinflussen lassen, etwa indem ihre Aktivierung verstärkt oder abgeschwächt wird. Dies kann sowohl für Analysezwecke als auch für Eingriffe in das Systemverhalten genutzt werden, ist jedoch bislang nur begrenzt kontrollierbar.
Grenzen des Verständnisses: Komplexität bleibt
Trotz dieser Fortschritte bleibt die Frage nach Transparenz offen. Einzelne Mechanismen zu verstehen bedeutet nicht, das Gesamtsystem vollständig zu durchdringen. Viele Erkenntnisse beziehen sich auf Teilaspekte oder auf vereinfachte Modelle.
Hinzu kommt eine zweite Ebene: die praktische Zugänglichkeit. Während in der Forschung gezielte Analysen möglich sind, bleibt im Alltag meist unklar, welche konkreten Gewichtungen zu einer bestimmten Antwort geführt haben. Für Nutzerinnen und Nutzer entsteht daher weiterhin der Eindruck einer Black Box.
Diese Diskrepanz verweist auf ein grundlegendes Problem: Ein System kann in Teilen erklärbar sein, ohne dass diese Erklärbarkeit im Alltag tatsächlich nutzbar wird.
Abschied von der Black Box?
Vor diesem Hintergrund lässt sich die Ausgangsfrage nicht eindeutig beantworten. Aus wissenschaftlicher Perspektive ist das Bild einer vollständig undurchsichtigen KI kaum noch haltbar. Die grundlegende Architektur ist verstanden, zentrale Mechanismen sind beschrieben, und erste Einblicke in interne Prozesse sind möglich.
Gleichzeitig bleibt die Erfahrung von Intransparenz bestehen. Die Komplexität der Systeme und die begrenzte Zugänglichkeit ihrer inneren Abläufe führen dazu, dass viele Entscheidungen nicht im Detail nachvollzogen werden können.
Ein angemessenes Verständnis liegt daher zwischen diesen Polen: KI-Systeme sind keine Black Boxes im strengen Sinne mehr, aber sie bleiben hochkomplexe, nur teilweise erschließbare Systeme – insbesondere aus Sicht der Anwenderinnen und Anwender.
Konsequenzen für die Nutzung
Diese Verschiebung hat praktische Folgen. Ein grundlegendes Verständnis der Funktionsweise ermöglicht eine gezieltere Nutzung. Präzise formulierte Eingaben führen häufig zu stabileren und nachvollziehbareren Ergebnissen, weil sie den Kontext stärker eingrenzen und damit die relevanten Gewichtungen klarer definieren.
Damit verbunden ist die Annahme, dass präzisere Anfragen auch ressourcenschonender sein könnten, da weniger irrelevante Aktivierungen stattfinden. Diese These wird diskutiert, ist jedoch bislang nur eingeschränkt empirisch abgesichert. Effizienzgewinne sind möglich, lassen sich aber nicht pauschal quantifizieren.
Zugleich relativiert sich ein häufiges Argument: Der Verweis auf die „Black Box“ als Begründung für grundlegende Unsicherheit greift zu kurz. Die Systeme sind nicht prinzipiell unverständlich, sondern noch nicht vollständig entschlüsselt. Risiken entstehen weniger aus völliger Intransparenz als aus der Kombination von Komplexität, Skalierung und Anwendungskontext.
Dazu zählen weiterhin konkrete Sicherheitsfragen, etwa durch Prompt-Injection oder gezielte Manipulationen von Systemverhalten. Dabei werden Eingaben so formuliert, dass sie das Modell dazu bringen, interne Regeln zu umgehen oder unerwünschte Ausgaben zu erzeugen. Diese Risiken zeigen, dass ein besseres technisches Verständnis allein nicht ausreicht. Es braucht ergänzend klare Rahmenbedingungen, Kompetenz im Umgang und eine kritische Einordnung der Ergebnisse.
Ein Vergleich verdeutlicht dies: Auch das menschliche Gehirn ist in vielen seiner Entscheidungsprozesse nur teilweise verstanden. Dennoch ist ein reflektierter und kritischer Umgang mit Aussagen und Verhalten möglich und notwendig.